library(tidyverse)Table of Content
- 1 Introduction
- 2 gather() and spread()
- 3 separate() and unite()
- 4 delete() and omit()
- 5 Conclusion
1 Introduction
Die meisten Datensätze mit denen man arbeiten möchte enthalten “unsaubere” Daten. Diese zu bereinigen, stellt demnach eine zentrale Tätigkeit in der Datenanalyse dar. In diesem Beitrag sollen folgende drei Methoden für eine saubere Aufbereitung des Datensatzes vorgesellt werden:
- gather() and spread()
- separate() and unite()
- delete() and omit()
Für diesen Post wurde der Datensatz IMDB-Movie-Data von der Statistik Plattform “Kaggle” verwendet. Eine Kopie des Datensatzes ist unter https://drive.google.com/open?id=13ytotLAXb70lgYHnblPbUWr9cb2z7SaN abrufbar.
movie <- read_csv("IMDB-Movie-Data.csv")2 gather() and spread()
Gathering
Es wird folgender Datensatz erstellt.
Name <- c("Martin", "Veronika", "Susanne", "Tom", "Vincent")
Y2014 <- c("48cm", "43cm", "44cm", "49cm", "52cm")
Y2015 <- c("59cm", "58cm", "60cm", "72cm", "70cm")
Y2016 <- c("80cm", "77cm", "80cm", "85cm", "90cm")
Y2017 <- c("92cm", "90cm", "82cm", "95cm", "100cm")
Y2018 <- c("105cm", "107cm", "103cm", "104cm", "116cm")
Datensatz1 <- data.frame(Name, Y2014, Y2015, Y2016, Y2017, Y2018)
Datensatz1## Name Y2014 Y2015 Y2016 Y2017 Y2018
## 1 Martin 48cm 59cm 80cm 92cm 105cm
## 2 Veronika 43cm 58cm 77cm 90cm 107cm
## 3 Susanne 44cm 60cm 80cm 82cm 103cm
## 4 Tom 49cm 72cm 85cm 95cm 104cm
## 5 Vincent 52cm 70cm 90cm 100cm 116cmGemessen wurde die Größe von Neugeborenen im Jahre 2014. Jedes weitere Jahr wurde erneut eine Messung durchgeführt und dokumentiert. Man kann auf diese Weise wunderbar das beispielsweise prozentuale Wachstum von Messung zu Messung berechnen. Was man mit dieser Aufteilung des Datensatzes nicht machen kann, ist eine analytische Betrachtung einer einzelnen Person, da die zugehörigen Daten über mehrere Variablen verstreut sind. Der gather Befehl löst dieses Problem, da man mit ihm einen bestehenden Datensatz neu formatieren kann (von einem breiten Format in ein langes Format).
df.awkward <- Datensatz1 %>% gather(Y2014, Y2015, Y2016, Y2017, Y2018, key = "Lebensjahr", value = "Größe")## Warning: attributes are not identical across measure variables;
## they will be droppeddf.awkward## Name Lebensjahr Größe
## 1 Martin Y2014 48cm
## 2 Veronika Y2014 43cm
## 3 Susanne Y2014 44cm
## 4 Tom Y2014 49cm
## 5 Vincent Y2014 52cm
## 6 Martin Y2015 59cm
## 7 Veronika Y2015 58cm
## 8 Susanne Y2015 60cm
## 9 Tom Y2015 72cm
## 10 Vincent Y2015 70cm
## 11 Martin Y2016 80cm
## 12 Veronika Y2016 77cm
## 13 Susanne Y2016 80cm
## 14 Tom Y2016 85cm
## 15 Vincent Y2016 90cm
## 16 Martin Y2017 92cm
## 17 Veronika Y2017 90cm
## 18 Susanne Y2017 82cm
## 19 Tom Y2017 95cm
## 20 Vincent Y2017 100cm
## 21 Martin Y2018 105cm
## 22 Veronika Y2018 107cm
## 23 Susanne Y2018 103cm
## 24 Tom Y2018 104cm
## 25 Vincent Y2018 116cmNoch einfacher geht es auf diese Weise.
df.easy <- gather(Datensatz1, Lebensjahr, Größe, -Name) ## Warning: attributes are not identical across measure variables;
## they will be droppeddf.easy## Name Lebensjahr Größe
## 1 Martin Y2014 48cm
## 2 Veronika Y2014 43cm
## 3 Susanne Y2014 44cm
## 4 Tom Y2014 49cm
## 5 Vincent Y2014 52cm
## 6 Martin Y2015 59cm
## 7 Veronika Y2015 58cm
## 8 Susanne Y2015 60cm
## 9 Tom Y2015 72cm
## 10 Vincent Y2015 70cm
## 11 Martin Y2016 80cm
## 12 Veronika Y2016 77cm
## 13 Susanne Y2016 80cm
## 14 Tom Y2016 85cm
## 15 Vincent Y2016 90cm
## 16 Martin Y2017 92cm
## 17 Veronika Y2017 90cm
## 18 Susanne Y2017 82cm
## 19 Tom Y2017 95cm
## 20 Vincent Y2017 100cm
## 21 Martin Y2018 105cm
## 22 Veronika Y2018 107cm
## 23 Susanne Y2018 103cm
## 24 Tom Y2018 104cm
## 25 Vincent Y2018 116cmNun kann man Auswertungen (z.B. die Entwicklung über die Jahre hinweg) pro Person vornehmen.
Beispiel1 <- df.easy %>% filter(Name == "Vincent")
Beispiel1$Größe <- str_replace(Beispiel1$Größe, "cm", "0")
Beispiel2 <- as.numeric(Beispiel1$Größe)
Beispiel3 <- Beispiel2/10
Beispiel3 %>% plot(type="l", main = "Entwicklung von Vincent", xlab = "Lebensjahre", ylab="Größe in cm")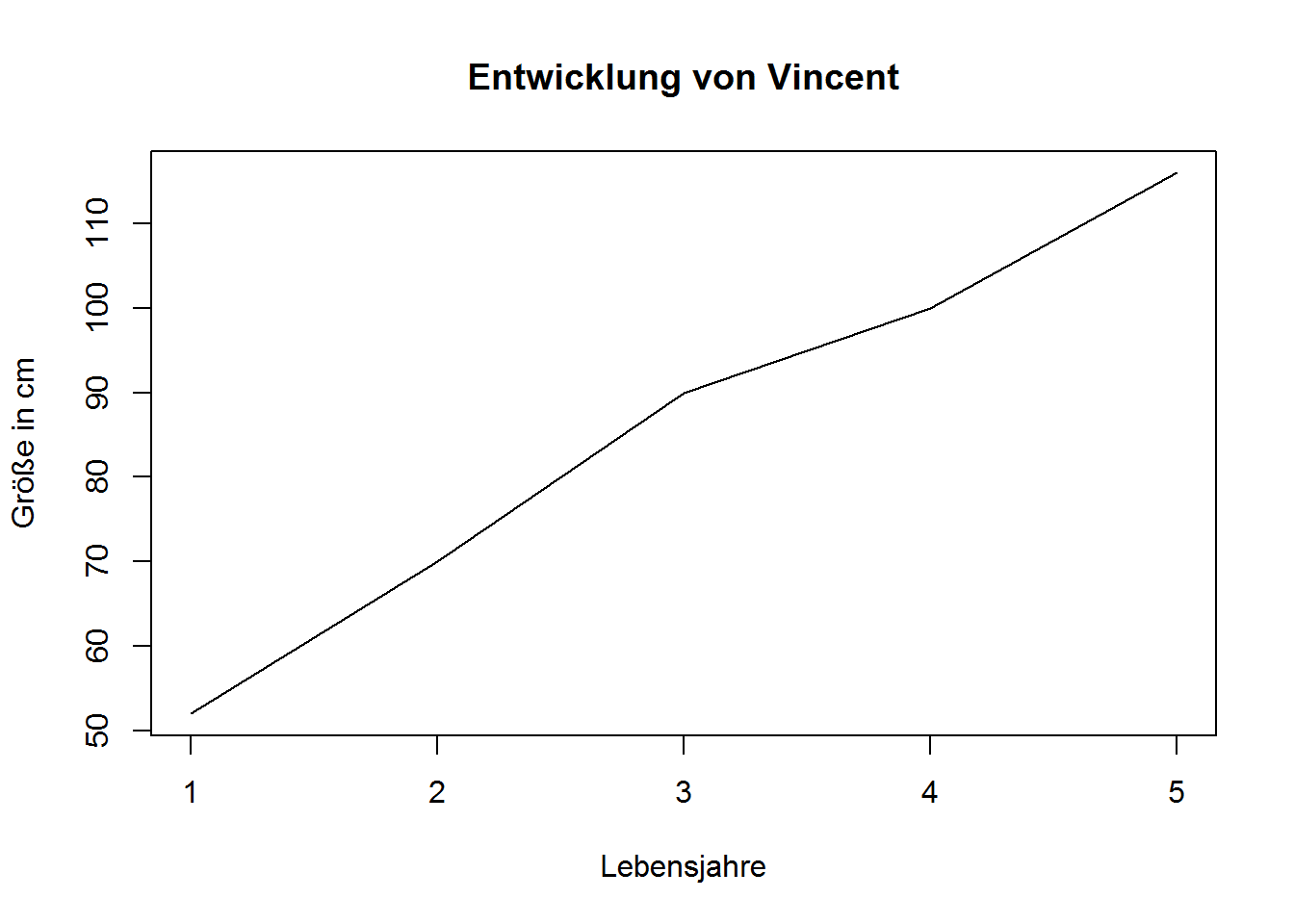
Spreading
Der Befehl spread() bewirkt genau das Gegenteil von gather(). Er bringt ein langes Format in ein breites. Es wird folgender Beispieldatensatz neu kreiert.
name <- c("Martin", "Martin", "Veronika", "Veronika", "Susanne", "Susanne", "Tom", "Tom", "Vincent", "Vincent")
type <- c("hight", "weight", "hight", "weight", "hight", "weight", "hight", "weight", "hight", "weight")
count <- c(180, 75, 185, 90, 165, 60, 170, 69, 180, 70)
Datensatz2 <- data.frame(name, type, count)
Datensatz2## name type count
## 1 Martin hight 180
## 2 Martin weight 75
## 3 Veronika hight 185
## 4 Veronika weight 90
## 5 Susanne hight 165
## 6 Susanne weight 60
## 7 Tom hight 170
## 8 Tom weight 69
## 9 Vincent hight 180
## 10 Vincent weight 70Für eine Auswertung soll der Mittelwert für die Größe und des Gewichts der Versuchsteilnehmer berechnet werden. Dafür muss der Datensatz erneut umformatiert werden. Benötigt werden eigene Spalten für die Variablen “hight” und “weight” pro Person.
df.long.syntax <- Datensatz2 %>% spread(key=type, value=count)
df.long.syntax## name hight weight
## 1 Martin 180 75
## 2 Susanne 165 60
## 3 Tom 170 69
## 4 Veronika 185 90
## 5 Vincent 180 70Die Zusatzargumente key= und value= werden von R automatisch erkannt und können daher auch weggelassen werden.
df.short.syntax <- Datensatz2 %>% spread(type, count)
df.short.syntax## name hight weight
## 1 Martin 180 75
## 2 Susanne 165 60
## 3 Tom 170 69
## 4 Veronika 185 90
## 5 Vincent 180 70Nun können die Mittelwerte berechnet werden.
mean(df.short.syntax$hight)## [1] 176mean(df.short.syntax$weight)## [1] 72.83 separate() and unite()
Separating
Für die Vorstellung des separate() Befehls wird die Spalte Genre aus dem Datensatz IMDB-Movie-Data verwendet.
head(movie$Genre)## [1] "Action,Adventure,Sci-Fi" "Adventure,Mystery,Sci-Fi"
## [3] "Horror,Thriller" "Animation,Comedy,Family"
## [5] "Action,Adventure,Fantasy" "Action,Adventure,Fantasy"Den verschiedenen Filmen wurden mehrere Genres zugeordnet. Bedauerlicherweise wurden alle Bezeichnungen in einer Variablen zusammengefasst. Für eine Auswertung der Hauptgenres (das Genre was an erster Stelle genannt wird) müssen die Begriffe erstmal voneinander getrennt werden. separate() macht genau dies für uns.
df.sep <- movie %>% separate(Genre, into = c("main genre", "further genre1", "further genre2")) ## Warning: Expected 3 pieces. Additional pieces discarded in 110 rows [1,
## 2, 13, 20, 25, 33, 35, 36, 37, 49, 61, 65, 68, 81, 86, 95, 98, 103, 110,
## 122, ...].## Warning: Expected 3 pieces. Missing pieces filled with `NA` in 332 rows
## [3, 8, 18, 19, 22, 26, 28, 29, 31, 32, 40, 42, 43, 45, 47, 50, 53, 58, 60,
## 69, ...].df.sep %>% select(`main genre`, `further genre1`, `further genre2`) %>% head## # A tibble: 6 x 3
## `main genre` `further genre1` `further genre2`
## <chr> <chr> <chr>
## 1 Action Adventure Sci
## 2 Adventure Mystery Sci
## 3 Horror Thriller <NA>
## 4 Animation Comedy Family
## 5 Action Adventure Fantasy
## 6 Action Adventure FantasyDer separate() Befehl ist ziemlich simple aufgebaut. Im ersten Argument wird die aufzuteilende Spalte aus dem Datensatz genannt. Anschließend wird bestimmt, unter welchen neuen Variablen die Aufspaltung abgespeichert werden soll. Betrachtet man die Spalte further genre2 fällt auf, dass in den ersten beiden Zeilen die Bezeichnung “Sci” genannt wird. Eigentlich sollte dort “Sci-Fi” (für Science Fiction) stehen. Dies kommt daher, weil wir R nicht mitgeteilt haben, an welcher Stelle es die Aufteilung vornehmen soll. Der R Befehl wird daher durch das Zusatzargument sep= ergänzt.
df.sep2 <- movie %>% separate(Genre, into = c("main genre", "further genre1", "further genre2"), sep = ",")## Warning: Expected 3 pieces. Missing pieces filled with `NA` in 340 rows
## [3, 8, 18, 19, 22, 26, 28, 29, 31, 32, 40, 42, 43, 45, 47, 50, 53, 58, 60,
## 69, ...].df.sep2 %>% select(`main genre`, `further genre1`, `further genre2`) %>% head## # A tibble: 6 x 3
## `main genre` `further genre1` `further genre2`
## <chr> <chr> <chr>
## 1 Action Adventure Sci-Fi
## 2 Adventure Mystery Sci-Fi
## 3 Horror Thriller <NA>
## 4 Animation Comedy Family
## 5 Action Adventure Fantasy
## 6 Action Adventure FantasyNun passt das Ergebnis. Filme, denen nur zwei Genres zugeordnet wurden (siehe Film Nummer 3), erhalten in der Spalte further genre2 (Spalte für das dritte Genre) einen fehlenden Wert. Abschließend wird eine graphische Übersicht über die Hauptgenres erstellt.
df.sep2.count <- df.sep2 %>% count(`main genre`)
ggplot(data=df.sep2.count, aes(x=`main genre`, y=n)) +
geom_bar(stat="identity", width=0.5) + coord_flip()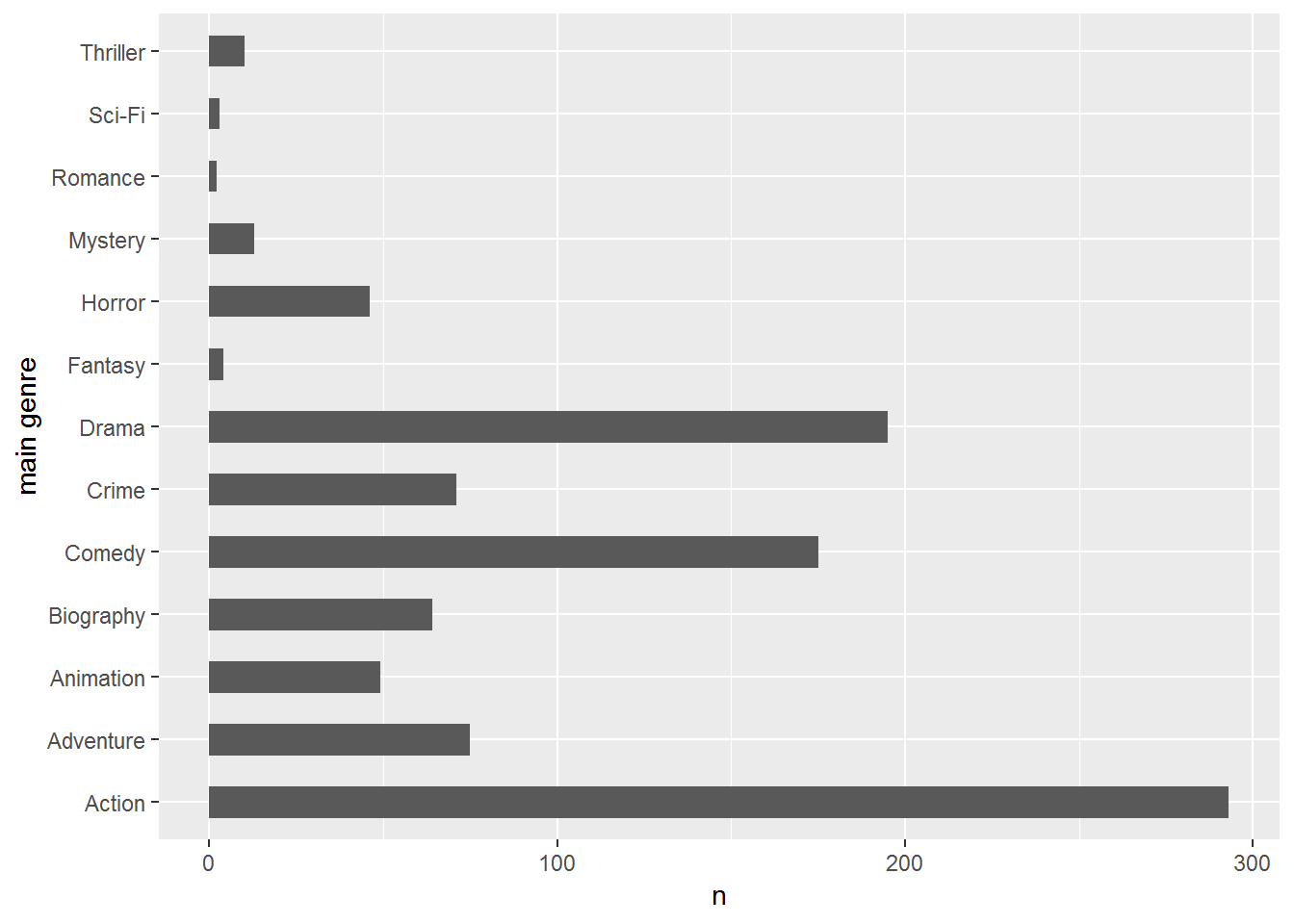
An dieser Stelle sollte erwähnt werden, dass der separate() Befehl einen entscheidenden Nachteil hat. Um diesen zu demonstrieren, werden die Schauspieler der jeweiligen Filme untersucht. Auch diese sind in einer Variablen zusammengefasst worden und werden nun aufgeteilt.
df.sep.actor <- movie %>% separate(Actors, into = c("first", "second", "third", "fourth"), sep = ",") %>% select(first, second, third, fourth)## Warning: Expected 4 pieces. Missing pieces filled with `NA` in 1 rows
## [623].df.sep.actor## # A tibble: 1,000 x 4
## first second third fourth
## <chr> <chr> <chr> <chr>
## 1 Chris Pratt " Vin Diesel" " Bradley Cooper" " Zoe Saldana"
## 2 Noomi Rapace " Logan Marshall-G~ " Michael Fassbe~ " Charlize Ther~
## 3 James McAvoy " Anya Taylor-Joy" " Haley Lu Richa~ " Jessica Sula"
## 4 Matthew McConau~ Reese Witherspoon " Seth MacFarlan~ " Scarlett Joha~
## 5 Will Smith " Jared Leto" " Margot Robbie" " Viola Davis"
## 6 Matt Damon " Tian Jing" " Willem Dafoe" " Andy Lau"
## 7 Ryan Gosling " Emma Stone" " Rosemarie DeWi~ " J.K. Simmons"
## 8 Essie Davis " Andrea Riseborou~ " Julian Barratt" Kenneth Branagh
## 9 Charlie Hunnam " Robert Pattinson" " Sienna Miller" " Tom Holland"
## 10 Jennifer Lawren~ " Chris Pratt" " Michael Sheen" Laurence Fishbu~
## # ... with 990 more rowsEs soll untersucht werden, in wie vielen Filmen der Schauspieler Bradley Cooper mitgewirkt hat und ob dieser als erster (Haupt-) Schauspieler nominiert wurde oder eine kleinere Rolle innehatte. Um dies herauszufinden, wird der Filterbefehl auf alle vier Spalten angewendet.
df.sep.actor.bc <- df.sep.actor %>% filter(first == "Bradley Cooper" | second == "Bradley Cooper" | third == "Bradley Cooper" | fourth == "Bradley Cooper")
df.sep.actor.bc %>% select(first, second, third, fourth)## # A tibble: 4 x 4
## first second third fourth
## <chr> <chr> <chr> <chr>
## 1 Bradley Cooper " Sienna Miller" " Kyle Gallner" " Cole Konis"
## 2 Bradley Cooper " Jennifer Lawrenc~ " Robert De Nir~ " Jacki Weaver"
## 3 Bradley Cooper " Anna Friel" " Abbie Cornish" " Robert De Niro"
## 4 Bradley Cooper " Sienna Miller" " Daniel Brühl" " Riccardo Scamarci~Als Ergebnis werden vier Filme angezeigt und auch nur mit Bradley Cooper als Hauptdarsteller. Hatte er in der vergangenheit keine weiteren Rollen bekommen oder stimmt etwas mit dem Filterbefehl nicht? Zur Beantwortung der Frage, wird ein Auszug aus der zweiten Spalte (second) erstellt (alternativ geht Spalte drei und vier natürlich auch).
head(df.sep.actor$second)## [1] " Vin Diesel" " Logan Marshall-Green" " Anya Taylor-Joy"
## [4] "Reese Witherspoon" " Jared Leto" " Tian Jing"Man erkennt hierbei, dass durch die Spaltung mittels dem separate() Befehls, teilweise Leerzeichen vor den Namen entstanden sind. Die zuvor verwendeten Filterbefehle für die Spalten second, third und fourth werden entsprechend abgeändert (durch Ergänzung von Leerzeichen vor dem Namen) und erneut durchgeführt.
df.sep.actor.bc2 <- df.sep.actor %>% filter(first == "Bradley Cooper" | second == " Bradley Cooper" | third == " Bradley Cooper" | fourth == " Bradley Cooper")
df.sep.actor.bc2 %>% select(first, second, third, fourth)## # A tibble: 11 x 4
## first second third fourth
## <chr> <chr> <chr> <chr>
## 1 Chris Pratt " Vin Diesel" " Bradley Coop~ " Zoe Saldana"
## 2 Ryan Gosling " Bradley Cooper" " Eva Mendes" Craig Van Hook
## 3 Zach Galifianak~ " Bradley Cooper" " Justin Barth~ " Ed Helms"
## 4 Bradley Cooper " Sienna Miller" " Kyle Gallner" " Cole Konis"
## 5 Bradley Cooper " Jennifer Lawren~ " Robert De Ni~ " Jacki Weaver"
## 6 Christian Bale " Amy Adams" " Bradley Coop~ Jennifer Lawrence
## 7 Jennifer Lawren~ " Robert De Niro" " Bradley Coop~ " Edgar Ramírez"
## 8 Bradley Cooper " Anna Friel" " Abbie Cornis~ " Robert De Niro"
## 9 Bradley Cooper " Sienna Miller" " Daniel Brühl" " Riccardo Scamarc~
## 10 Liam Neeson " Bradley Cooper" " Sharlto Copl~ Jessica Biel
## 11 Vinnie Jones " Bradley Cooper" " Leslie Bibb" " Brooke Shields"Dieses Ergebnis wirkt realistischer. Allerdings merkt man, dass der Filterbefehl hier nicht mehr so zuverlässig eingesetzt werden kann. Abhilfe leistet die str_detect() Funktion. Diese stammt aus dem Data Mining Bereich und regiert nicht so sensibel wie filter(). Bedeutet in unserem Fall, dass Leerzeichen automatisch ignoriert werden.
df.sep.actor.bc3 <- df.sep.actor %>% select(first, second, third, fourth) %>% filter(str_detect(first, "Bradley Cooper") | str_detect(second, "Bradley Cooper") | str_detect(third, "Bradley Cooper") | str_detect(fourth, "Bradley Cooper"))
df.sep.actor.bc3## # A tibble: 11 x 4
## first second third fourth
## <chr> <chr> <chr> <chr>
## 1 Chris Pratt " Vin Diesel" " Bradley Coop~ " Zoe Saldana"
## 2 Ryan Gosling " Bradley Cooper" " Eva Mendes" Craig Van Hook
## 3 Zach Galifianak~ " Bradley Cooper" " Justin Barth~ " Ed Helms"
## 4 Bradley Cooper " Sienna Miller" " Kyle Gallner" " Cole Konis"
## 5 Bradley Cooper " Jennifer Lawren~ " Robert De Ni~ " Jacki Weaver"
## 6 Christian Bale " Amy Adams" " Bradley Coop~ Jennifer Lawrence
## 7 Jennifer Lawren~ " Robert De Niro" " Bradley Coop~ " Edgar Ramírez"
## 8 Bradley Cooper " Anna Friel" " Abbie Cornis~ " Robert De Niro"
## 9 Bradley Cooper " Sienna Miller" " Daniel Brühl" " Riccardo Scamarc~
## 10 Liam Neeson " Bradley Cooper" " Sharlto Copl~ Jessica Biel
## 11 Vinnie Jones " Bradley Cooper" " Leslie Bibb" " Brooke Shields"Abschließend wird noch der Frage nachgegangen, wie häufig und mit welcher Nominierung Cooper mitgewirkt hat.
df.sep.actor.bc3 %>% str_count("Bradley Cooper")## [1] 4 4 3 0df.sep.actor.bc3 %>% str_count("Bradley Cooper") %>% barplot(main="Filme von Cooper", names.arg=c("first", "second", "third", "fourth"), cex.names=0.8, ylab="count")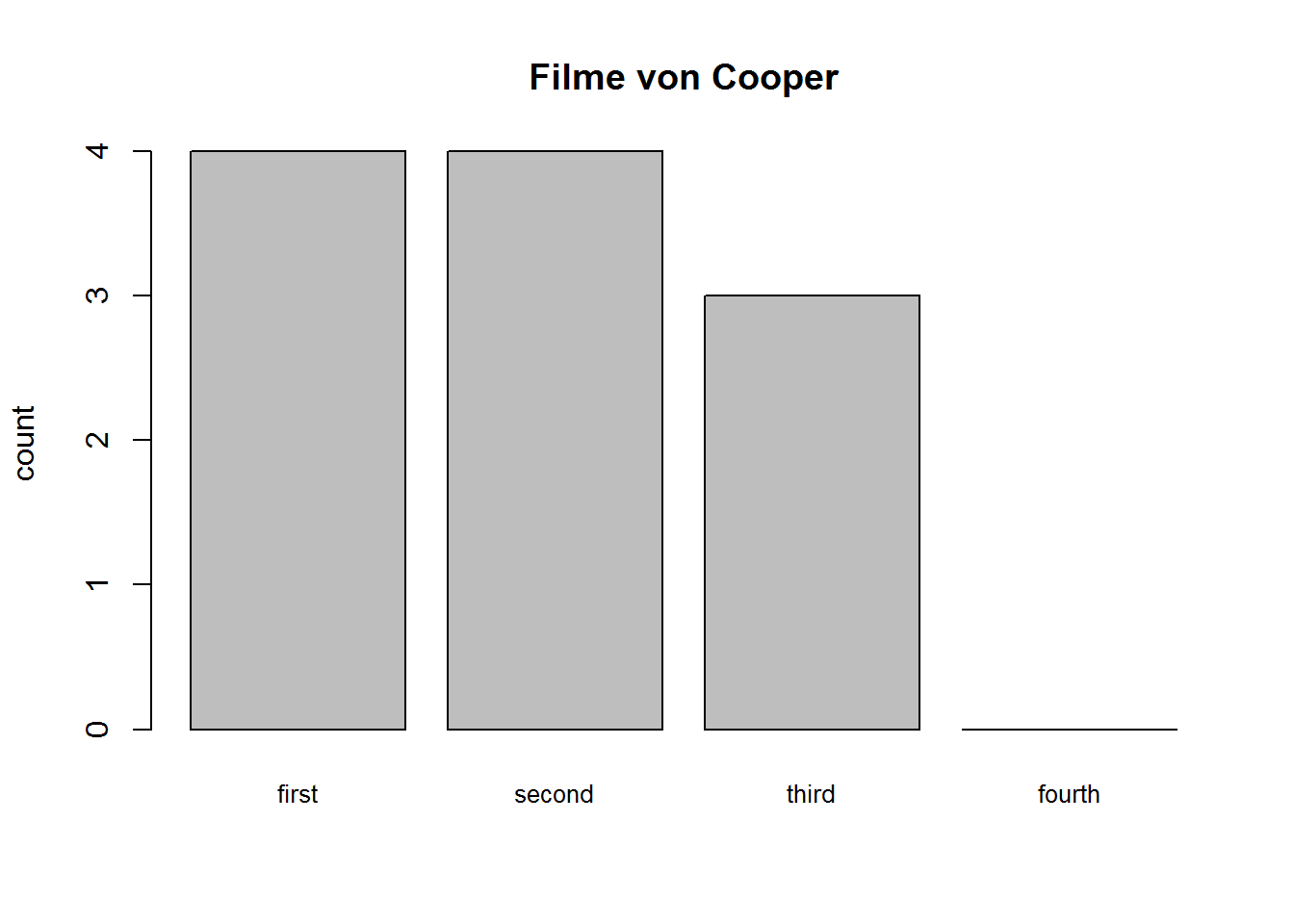
Unite
Manchmal kann es sinnvoll sein, gewisse Spalten eines Datensatzes zusammen zu führen.
movie %>% select(Rating, Votes) %>% head() ## # A tibble: 6 x 2
## Rating Votes
## <dbl> <int>
## 1 8.1 757074
## 2 7 485820
## 3 7.3 157606
## 4 7.2 60545
## 5 6.2 393727
## 6 6.1 56036unite macht genau dies. Das erste Argument der Funktion beinhaltet den neuen Namen der erstellten Variablen. Anschließend werden die beiden Spalten aus dem Datensatz benannt, welche zusammengeführt werden sollen. Abschließend wird mit sep= bestimmt, durch welches Zeichen die Werte getrennt werden sollen.
df.unite <- movie %>% unite(Rating/Votes, Rating, Votes, sep = "/") %>%
select(`Rating/Votes`) %>%
head()
df.unite## # A tibble: 6 x 1
## `Rating/Votes`
## <chr>
## 1 8.1/757074
## 2 7/485820
## 3 7.3/157606
## 4 7.2/60545
## 5 6.2/393727
## 6 6.1/560364 delete() and omit()
Delete
Nicht immer werden alle Spalten oder Zeilen eines Datensatzes benötigt. Sie können daher gezielt gelöscht werden.
Folgendes Beispiel zeigt die Löschung der vierten Spalte (Description) aus dem Datensatz IMDB-Movie-Data.
del <- movie[, -(4)]
del## # A tibble: 1,000 x 11
## Rank Title Genre Director Actors Year `Runtime (Minut~ Rating Votes
## <int> <chr> <chr> <chr> <chr> <int> <int> <dbl> <int>
## 1 1 Guar~ Acti~ James G~ Chris~ 2014 121 8.1 757074
## 2 2 Prom~ Adve~ Ridley ~ Noomi~ 2012 124 7 485820
## 3 3 Split Horr~ M. Nigh~ James~ 2016 117 7.3 157606
## 4 4 Sing Anim~ Christo~ Matth~ 2016 108 7.2 60545
## 5 5 Suic~ Acti~ David A~ Will ~ 2016 123 6.2 393727
## 6 6 The ~ Acti~ Yimou Z~ Matt ~ 2016 103 6.1 56036
## 7 7 La L~ Come~ Damien ~ Ryan ~ 2016 128 8.3 258682
## 8 8 Mind~ Come~ Sean Fo~ Essie~ 2016 89 6.4 2490
## 9 9 The ~ Acti~ James G~ Charl~ 2016 141 7.1 7188
## 10 10 Pass~ Adve~ Morten ~ Jenni~ 2016 116 7 192177
## # ... with 990 more rows, and 2 more variables: `Revenue
## # (Millions)` <dbl>, Metascore <int>Es können auch gezielt die ersten 6 Zeilen entfernt werden, sodass der Datensatz erst bei Rank 7 beginnt.
del2 <- movie[-(1:6), ]
del2## # A tibble: 994 x 12
## Rank Title Genre Description Director Actors Year `Runtime (Minut~
## <int> <chr> <chr> <chr> <chr> <chr> <int> <int>
## 1 7 La L~ Come~ A jazz pia~ Damien ~ Ryan ~ 2016 128
## 2 8 Mind~ Come~ "A has-bee~ Sean Fo~ Essie~ 2016 89
## 3 9 The ~ Acti~ A true-lif~ James G~ Charl~ 2016 141
## 4 10 Pass~ Adve~ A spacecra~ Morten ~ Jenni~ 2016 116
## 5 11 Fant~ Adve~ The advent~ David Y~ Eddie~ 2016 133
## 6 12 Hidd~ Biog~ The story ~ Theodor~ Taraj~ 2016 127
## 7 13 Rogu~ Acti~ The Rebel ~ Gareth ~ Felic~ 2016 133
## 8 14 Moana Anim~ In Ancient~ Ron Cle~ Auli'~ 2016 107
## 9 15 Colo~ Acti~ Gloria is ~ Nacho V~ Anne ~ 2016 109
## 10 16 The ~ Anim~ The quiet ~ Chris R~ Louis~ 2016 87
## # ... with 984 more rows, and 4 more variables: Rating <dbl>, Votes <int>,
## # `Revenue (Millions)` <dbl>, Metascore <int>Omit
Ist man sich unsicher, ob die Daten noch benötigt werden oder nicht, besteht die Möglichkeit relevante Informationen gezielt zu extrahieren. Dies kann wieder spaltenweise als auch zeilenweise durchgeführt werden.
movie[1:3, ]## # A tibble: 3 x 12
## Rank Title Genre Description Director Actors Year `Runtime (Minut~
## <int> <chr> <chr> <chr> <chr> <chr> <int> <int>
## 1 1 Guar~ Acti~ A group of~ James G~ Chris~ 2014 121
## 2 2 Prom~ Adve~ Following ~ Ridley ~ Noomi~ 2012 124
## 3 3 Split Horr~ Three girl~ M. Nigh~ James~ 2016 117
## # ... with 4 more variables: Rating <dbl>, Votes <int>, `Revenue
## # (Millions)` <dbl>, Metascore <int>movie[, 5]## # A tibble: 1,000 x 1
## Director
## <chr>
## 1 James Gunn
## 2 Ridley Scott
## 3 M. Night Shyamalan
## 4 Christophe Lourdelet
## 5 David Ayer
## 6 Yimou Zhang
## 7 Damien Chazelle
## 8 Sean Foley
## 9 James Gray
## 10 Morten Tyldum
## # ... with 990 more rows5 Conclusion
Ein sauberer Datensatz weißt folgende Kriterien auf:
- Jede Variable bildet eine Spalte
- Jede Beobachtung bildet eine Reihe
- Jede Art von Beobachtungseinheit bildet eine Tabelle
Ist eines nicht gegeben, so sollte man für eine gute Auswertbarkeit des Datensatzes diesen entsprechend bereinigen. Die hier vorgestellten Befehle sowie die aus dem Post “Data Transformation in R” helfen dabei ungemein.