Table of Content
- 1 Introduction
- 2 Overview
- 2.1 filter()
- 2.2 select()
- 2.3 mutate()
- 2.4 arrange()
- 2.5 summarize()
- 3 Combinations
- 4 Conclusion
- 5 Bibliography
1 Introduction
In dem nachfolgenden Post geht es um Data Transformation in R. Je nach Blickwinkel fällt dieses Thema in den Bereich Data Data Wrangling oder Data Exploration (Wickham & Grolemund, 2016).
Quelle: Wickham, H., & Grolemund, G. (2016). R for data science: import, tidy, transform, visualize, and model data. " O’Reilly Media, Inc."
Quelle: Wickham, H., & Grolemund, G. (2016). R for data science: import, tidy, transform, visualize, and model data. " O’Reilly Media, Inc."
Hadley Wickham, einer der Autoren des Packages dplyr, definierte hierbei die folgenden 5 Verben:
- filter()
- select()
- mutate()
- arrange()
- summarize()
Für diese Arbeit wurde der Datensatz olympics von der Statistik-Plattform Kaggle https://www.kaggle.com verwendet. Eine Kopie des Datensatzes ist unter https://drive.google.com/open?id=1XsV3WVTb0EXjd9LhlpN2PkvUKJU8iY38 abrufbar.
library("tidyverse")olympics <- read_csv("olympics.csv")2 Overview
glimpse(olympics)## Observations: 271,116
## Variables: 15
## $ ID <int> 1, 2, 3, 4, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 7...
## $ Name <chr> "A Dijiang", "A Lamusi", "Gunnar Nielsen Aaby", "Edgar ...
## $ Sex <chr> "M", "M", "M", "M", "F", "F", "F", "F", "F", "F", "M", ...
## $ Age <int> 24, 23, 24, 34, 21, 21, 25, 25, 27, 27, 31, 31, 31, 31,...
## $ Height <int> 180, 170, NA, NA, 185, 185, 185, 185, 185, 185, 188, 18...
## $ Weight <dbl> 80, 60, NA, NA, 82, 82, 82, 82, 82, 82, 75, 75, 75, 75,...
## $ Team <chr> "China", "China", "Denmark", "Denmark/Sweden", "Netherl...
## $ NOC <chr> "CHN", "CHN", "DEN", "DEN", "NED", "NED", "NED", "NED",...
## $ Games <chr> "1992 Summer", "2012 Summer", "1920 Summer", "1900 Summ...
## $ Year <int> 1992, 2012, 1920, 1900, 1988, 1988, 1992, 1992, 1994, 1...
## $ Season <chr> "Summer", "Summer", "Summer", "Summer", "Winter", "Wint...
## $ City <chr> "Barcelona", "London", "Antwerpen", "Paris", "Calgary",...
## $ Sport <chr> "Basketball", "Judo", "Football", "Tug-Of-War", "Speed ...
## $ Event <chr> "Basketball Men's Basketball", "Judo Men's Extra-Lightw...
## $ Medal <chr> NA, NA, NA, "Gold", NA, NA, NA, NA, NA, NA, NA, NA, NA,...Wir haben es bei diesem Datensatz mit über 271k Observations zu tun. Dabei brauchen wir dieses Mal doch nur ganz ausgewählte Informationen… Mit den 5 oben genannten Befehlen lässt sich dies auch ganz leicht bewerkstelligen.
2.1 filter()
Mit dem Befehl filter() bekommen wir von R genau definierte Zeilen aus dem zugrunde liegenden Datensatz ausgegeben. Es gibt folgende Möglichkeiten zu filtern:
- ‘==’
- ‘!=’
- ‘<’
- ‘>’
- ‘<=’
‘>=’
- “&” heißt “und”
“|” heißt “oder”
Als anschauliches Beispiel wollen wir nun wissen, wie viele deutsche Olympiateilnahmen es bisher gab.
olympics %>% filter(NOC == "GER")## # A tibble: 9,830 x 15
## ID Name Sex Age Height Weight Team NOC Games Year Season
## <int> <chr> <chr> <int> <int> <dbl> <chr> <chr> <chr> <int> <chr>
## 1 133 Fran~ M NA NA NA Germ~ GER 1900~ 1900 Summer
## 2 389 Adol~ M 45 NA NA Germ~ GER 1928~ 1928 Summer
## 3 389 Adol~ M 45 NA NA Germ~ GER 1928~ 1928 Summer
## 4 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 5 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 6 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 7 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 8 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 9 402 Arth~ M 22 184 85 Germ~ GER 2008~ 2008 Summer
## 10 402 Arth~ M 30 184 85 Germ~ GER 2016~ 2016 Summer
## # ... with 9,820 more rows, and 4 more variables: City <chr>, Sport <chr>,
## # Event <chr>, Medal <chr>Nicht schlecht, doch fast 10.000 Teilnahmen. Und wie schaut es mit der Geschlechteraufteilung aus? Wir filtern zuerst nach den männlichen Teilnehmern. Dabei kann man den vorherigen Befehl mit einem &-Zeichen um ein weiteres Kriterium erweitern.
olympics %>% filter(NOC == "GER" & Sex == "M")## # A tibble: 6,831 x 15
## ID Name Sex Age Height Weight Team NOC Games Year Season
## <int> <chr> <chr> <int> <int> <dbl> <chr> <chr> <chr> <int> <chr>
## 1 133 Fran~ M NA NA NA Germ~ GER 1900~ 1900 Summer
## 2 389 Adol~ M 45 NA NA Germ~ GER 1928~ 1928 Summer
## 3 389 Adol~ M 45 NA NA Germ~ GER 1928~ 1928 Summer
## 4 402 Arth~ M 22 184 85 Germ~ GER 2008~ 2008 Summer
## 5 402 Arth~ M 30 184 85 Germ~ GER 2016~ 2016 Summer
## 6 505 "Ale~ M 25 186 84 Germ~ GER 1912~ 1912 Summer
## 7 508 Bern~ M NA NA NA Germ~ GER 1906~ 1906 Summer
## 8 561 Thom~ M 26 184 73 Germ~ GER 1994~ 1994 Winter
## 9 561 Thom~ M 26 184 73 Germ~ GER 1994~ 1994 Winter
## 10 586 Tobi~ M 31 178 85 Germ~ GER 2002~ 2002 Winter
## # ... with 6,821 more rows, and 4 more variables: City <chr>, Sport <chr>,
## # Event <chr>, Medal <chr>6,8k männliche Teilnehmer! Und jetzt die weiblichen mit dem gleichen Befehl leicht abgewandelt:
olympics %>% filter(NOC == "GER" & Sex != "M")## # A tibble: 2,999 x 15
## ID Name Sex Age Height Weight Team NOC Games Year Season
## <int> <chr> <chr> <int> <int> <dbl> <chr> <chr> <chr> <int> <chr>
## 1 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 2 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 3 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 4 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 5 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 6 769 Leon~ F 23 162 54 Germ~ GER 2016~ 2016 Summer
## 7 796 Sabi~ F 32 172 68 Germ~ GER 1992~ 1992 Summer
## 8 827 Mare~ F 26 174 73 Germ~ GER 2016~ 2016 Summer
## 9 893 Ulri~ F 23 170 60 Germ~ GER 1994~ 1994 Winter
## 10 981 Katr~ F 29 177 62 Germ~ GER 1996~ 1996 Summer
## # ... with 2,989 more rows, and 4 more variables: City <chr>, Sport <chr>,
## # Event <chr>, Medal <chr>!= bedeutet “nicht”. Wir sehen fast 3k weibliche Teilnehmer, die bisher an Olympia teilnahmen. Nun möchten wir wissen, wie viele deutsche Teilnehmer zwischen 20 und 30 Jahre alt waren:
olympics %>% filter(NOC == "GER" & Age >= 20 & Age <= 30)## # A tibble: 7,113 x 15
## ID Name Sex Age Height Weight Team NOC Games Year Season
## <int> <chr> <chr> <int> <int> <dbl> <chr> <chr> <chr> <int> <chr>
## 1 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 2 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 3 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 4 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 5 396 Katj~ F 25 165 55 Germ~ GER 2008~ 2008 Summer
## 6 402 Arth~ M 22 184 85 Germ~ GER 2008~ 2008 Summer
## 7 402 Arth~ M 30 184 85 Germ~ GER 2016~ 2016 Summer
## 8 505 "Ale~ M 25 186 84 Germ~ GER 1912~ 1912 Summer
## 9 561 Thom~ M 26 184 73 Germ~ GER 1994~ 1994 Winter
## 10 561 Thom~ M 26 184 73 Germ~ GER 1994~ 1994 Winter
## # ... with 7,103 more rows, and 4 more variables: City <chr>, Sport <chr>,
## # Event <chr>, Medal <chr>2.2 select()
Im Vergleich zu dem filter() Befehlt wählt select() nicht einzelne Zeilen, sondern ganze Spalten aus. Sehr häufig kommt es vor, dass Datensätze ganz viele Spalten besitzen, die man für die anstehende Analyse überhaupt nicht braucht. Um den Datensatz übersichtlicher zu gestalten, hat man mit select() die Möglichkeit einzelne Spalten gezielt auszuwählen.
Nachfolgend interessiert mich, ob es einen Zusammenhang zwischen der Körpergröße und dem Körpergewicht gibt. Daführ wähle ich genau diese beiden Spalten aus:
olympics %>% select(Height, Weight)## # A tibble: 271,116 x 2
## Height Weight
## <int> <dbl>
## 1 180 80
## 2 170 60
## 3 NA NA
## 4 NA NA
## 5 185 82
## 6 185 82
## 7 185 82
## 8 185 82
## 9 185 82
## 10 185 82
## # ... with 271,106 more rowsDa ich bei Korrelationen keine fehlenden Werte gebrauchen kann, lösche ich diese mit na.omit raus und lasse mir mit cor() die Stärke des Zusammenhanges ausgeben:
olympics %>% select(Height, Weight) %>% na.omit() %>% cor()## Height Weight
## Height 1.0000000 0.7962131
## Weight 0.7962131 1.0000000Alterntiv kann der Befehl auch so geschrieben werden:
olympics %>% select(Height, Weight) %>% cor(use = "complete.obs")## Height Weight
## Height 1.0000000 0.7962131
## Weight 0.7962131 1.0000000Bei r=0,8 kann man von einem starken Zusammenhang sprechen.
2.3 mutate()
Für und während des Analyseprozesses werden wir kaum drum herum kommen, neue Variablen aus dem Datensatz heraus zu kreieren. Der mutate() Befehl tut genau dies. Die Funktion ist wie folgt aufgebaut: mutate(“Name neuer Variable” = “Var1” plus/minus/geteilt “Var2”). Benutzt man nicht wie wir im nachfolgenden Beispiel die Pipe Funktion (%>%), muss vor dem Namen der neuen Variable der zugrunde liegende Datensatz genannt werden. Nachfolgend interessiert mich nun, welchen BMI (Body-Mass-Index) die Sportler hatten. Da der Datensatz diese Variable (noch) nicht hat, erzeugen wir sie eben selbst:
olympics %>% mutate(bmi = Weight / (Height/100)^2)## # A tibble: 271,116 x 16
## ID Name Sex Age Height Weight Team NOC Games Year Season
## <int> <chr> <chr> <int> <int> <dbl> <chr> <chr> <chr> <int> <chr>
## 1 1 A Di~ M 24 180 80 China CHN 1992~ 1992 Summer
## 2 2 A La~ M 23 170 60 China CHN 2012~ 2012 Summer
## 3 3 Gunn~ M 24 NA NA Denm~ DEN 1920~ 1920 Summer
## 4 4 Edga~ M 34 NA NA Denm~ DEN 1900~ 1900 Summer
## 5 5 Chri~ F 21 185 82 Neth~ NED 1988~ 1988 Winter
## 6 5 Chri~ F 21 185 82 Neth~ NED 1988~ 1988 Winter
## 7 5 Chri~ F 25 185 82 Neth~ NED 1992~ 1992 Winter
## 8 5 Chri~ F 25 185 82 Neth~ NED 1992~ 1992 Winter
## 9 5 Chri~ F 27 185 82 Neth~ NED 1994~ 1994 Winter
## 10 5 Chri~ F 27 185 82 Neth~ NED 1994~ 1994 Winter
## # ... with 271,106 more rows, and 5 more variables: City <chr>,
## # Sport <chr>, Event <chr>, Medal <chr>, bmi <dbl>2.4 arrange()
Für die Erläuterung des arrange() Befehls bleiben wir in unserer Analyse noch ein wenig bei der gerade neu erzeugten Variable ‘bmi’. Arrange() sortiert einen Vektor neu. Dies kann aufsteigend oder absteigend erfolgen:
olympics %>% mutate(bmi = Weight / (Height/100)^2) %>% arrange(bmi)## # A tibble: 271,116 x 16
## ID Name Sex Age Height Weight Team NOC Games Year Season
## <int> <chr> <chr> <int> <int> <dbl> <chr> <chr> <chr> <int> <chr>
## 1 134370 "Alb~ M 24 183 28 Unit~ USA 1956~ 1956 Summer
## 2 110533 Lia ~ F 31 169 30 Braz~ BRA 2016~ 2016 Summer
## 3 33539 Bndi~ F 17 176 38 Belg~ BEL 1992~ 1992 Summer
## 4 33539 Bndi~ F 17 176 38 Belg~ BEL 1992~ 1992 Summer
## 5 33539 Bndi~ F 17 176 38 Belg~ BEL 1992~ 1992 Summer
## 6 33539 Bndi~ F 17 176 38 Belg~ BEL 1992~ 1992 Summer
## 7 33539 Bndi~ F 17 176 38 Belg~ BEL 1992~ 1992 Summer
## 8 5381 Mart~ F 16 160 32 Spain ESP 1984~ 1984 Summer
## 9 5381 Mart~ F 16 160 32 Spain ESP 1984~ 1984 Summer
## 10 5381 Mart~ F 16 160 32 Spain ESP 1984~ 1984 Summer
## # ... with 271,106 more rows, and 5 more variables: City <chr>,
## # Sport <chr>, Event <chr>, Medal <chr>, bmi <dbl>Oh! Ein Mann mit 1,83m Körpergröße und nur 28kg Gewicht (bmi = 8,36) … komisch, das kann wohl nicht sein.
Nun das Ganze für einen absteigenden BMI Wert:
olympics %>% mutate(bmi = Weight / (Height/100)^2) %>% arrange(desc(bmi))## # A tibble: 271,116 x 16
## ID Name Sex Age Height Weight Team NOC Games Year Season
## <int> <chr> <chr> <int> <int> <dbl> <chr> <chr> <chr> <int> <chr>
## 1 12177 Rica~ M 21 183 214 Guam GUM 2008~ 2008 Summer
## 2 12177 Rica~ M 25 183 214 Guam GUM 2012~ 2012 Summer
## 3 87041 Dmit~ M 24 176 175 Russ~ RUS 2004~ 2004 Summer
## 4 45319 Shan~ M 28 173 161 Unit~ USA 2000~ 2000 Summer
## 5 45319 Shan~ M 32 173 161 Unit~ USA 2004~ 2004 Summer
## 6 74435 Holl~ F 22 173 155 Unit~ USA 2012~ 2012 Summer
## 7 103580 Vale~ M 28 187 180 Ukra~ UKR 2000~ 2000 Summer
## 8 62843 Olha~ F 18 181 167 Ukra~ UKR 2004~ 2004 Summer
## 9 62843 Olha~ F 22 181 167 Ukra~ UKR 2008~ 2008 Summer
## 10 103413 Leon~ M 29 187 178 Vene~ VEN 2004~ 2004 Summer
## # ... with 271,106 more rows, and 5 more variables: City <chr>,
## # Sport <chr>, Event <chr>, Medal <chr>, bmi <dbl>Nicht schlecht, wieder ein 1,83m großer Mann an der Spitze mit 214kg Körpergewicht. Aber dieses Mal handelt es sich um einen Judoka und das ist wiederum schon ein wenig realisitscher.
2.5 summarize()
Der Letzte der 5 hier behandelten Befehle für Data Transformation ist summarize(). Er wird fast ausschließlich mit dem group_by() Befehl verwendet. Diese Kombination ermöglicht Vergleiche. Wird summarize() alleine verwendet, bricht er den Dataframe auf eine einzelne Zeile herunter.
Tipp: Um sicher zu gehen, dass die Aggregation richtig erfolgt, verwende ich n() bei jedem summarize() Befehl:
olympics %>% summarize(N = n(), first_year = min(Year), last_year = max(Year), avg_age = mean(na.omit(Age)))## # A tibble: 1 x 4
## N first_year last_year avg_age
## <int> <dbl> <dbl> <dbl>
## 1 271116 1896 2016 25.6Wir sehen, dass die Olympischen Spiele ab 1896 in unserem Datensatz aufgeführt sind. Die letzten fanden 2016 statt. Durchschnittlich waren die Teilnehmer 25,6 Jahre alt.
Wie zuvor bereits erwähnt, erlaubt uns der summarize() Befehl in Verbindung mit dem group_by() Befehl zu vergleichen. Mit group_by wird eine Varibale des Datensatzes entsprechend groupiert:
olympics %>% group_by(Year) %>% summarize(N = n(), avg_age = mean(na.omit(Age)))## # A tibble: 35 x 3
## Year N avg_age
## <int> <int> <dbl>
## 1 1896 380 23.6
## 2 1900 1936 29.0
## 3 1904 1301 26.7
## 4 1906 1733 27.1
## 5 1908 3101 27.0
## 6 1912 4040 27.5
## 7 1920 4292 29.3
## 8 1924 5693 28.4
## 9 1928 5574 29.1
## 10 1932 3321 32.6
## # ... with 25 more rowsNun können wir das Durchschnittsalter der Athleten pro Jahr vergleichen.
3 Combinations
In der Praxis werden meist die Funktionen in Kombination miteinander benutzt:
olympics %>% filter(NOC == "GER") %>%
select(Age, Height, Weight, Year) %>%
mutate(bmi = Weight / (Height/100)^2) %>%
group_by(Year) %>%
summarize(N = n(), avg_bmi = mean(na.omit(bmi)))## # A tibble: 26 x 3
## Year N avg_bmi
## <int> <int> <dbl>
## 1 1896 94 24.5
## 2 1900 103 25.0
## 3 1904 55 23.9
## 4 1906 157 23.4
## 5 1908 148 21.6
## 6 1912 312 22.2
## 7 1928 450 22.4
## 8 1932 225 23.1
## 9 1936 648 22.9
## 10 1952 442 22.8
## # ... with 16 more rowsWas haben wir hierbei mit einem einzigen Befehl alles gemacht? Als Ergebnis sehen wir den durchschnittlichen BMI Wert von allen deutschen Olympiateilnehmern aufgeteilt nach Jahren.
Das Ganze ist auch ziemlich leicht und schnell graphisch dargestellt:
all<- olympics %>% filter(NOC == "GER") %>%
select(Age, Height, Weight, Year) %>%
mutate(bmi = Weight / (Height/100)^2) %>%
group_by(Year) %>%
summarize(N = n(), avg_bmi = mean(na.omit(bmi)))
plot(all$Year, all$avg_bmi, type = "l")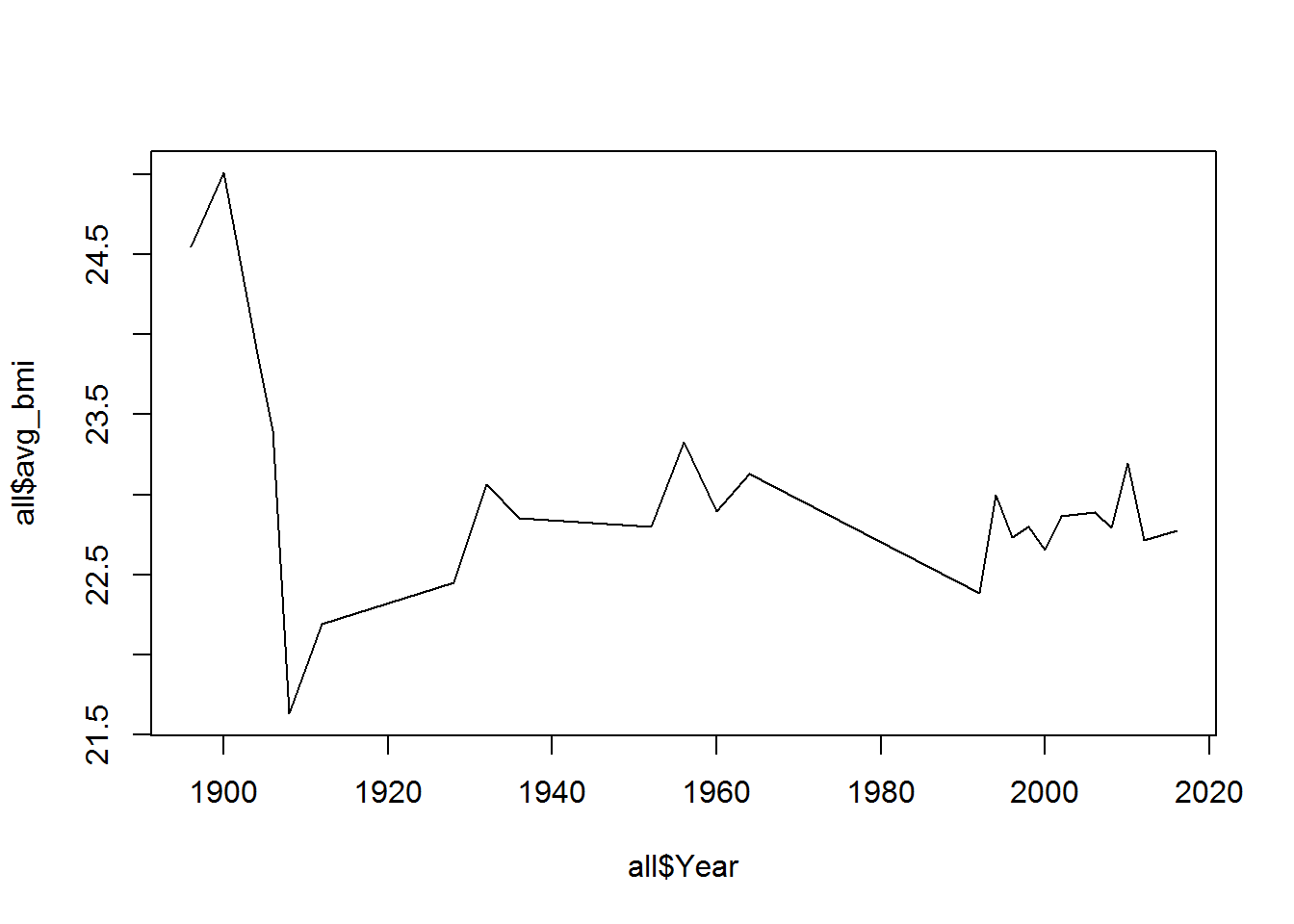
4 Conclusion
Mit nur sehr wenigen Befehlen, kann man schon recht viel in Sachen Datentransformation erreichen. Wie man anhand des letzten Beispiels gesehen hat, harmonieren die Packages ‘dplyr’ und ‘ggplot2’ sehr gut miteinander.
5 Bibliography
Wickham, H., & Grolemund, G. (2016). R for data science: import, tidy, transform, visualize, and model data. " O’Reilly Media, Inc.“.